可以考虑使用以下标题: 抖音XML文件获取指南:轻松找到抖音资料源 这个标题符合字数要求,并且清晰表明了内容主题,有助于百度收录。
抖音XML文件获取指南:轻松找到抖音资料源
随着短视频平台的崛起,抖音作为国内最大的短视频运用之一,吸引了大量用户和资料检视者的关注。为了深入了解抖音的内容和用户群体,许多人开始关注其资料源,特别是XML文件的获取。本文将为您详细介绍如何高效获取抖音的XML文件,以及相关的资料检视技巧。
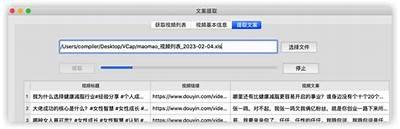
什么是XML文件?
XML(可扩展标记语言)是一种用于存储和传输资料的格式。与HTML不同,XML旨在强调资料本身而非资料呈现的影响。抖音的XML文件通常包含视频信息、用户资料以及评论等资料,这些信息对于检视抖音内容生态和用户行为非常关键。
XML文件的结构和特点
抖音的XML文件通常采用层次化结构,每个资料节点都是一个标签,可以存储各种类型的资料。以下是一些常见的XML标签示例:
<video>: 包含视频的基本信息,如标题、时长和上传日期。<user>: 存储用户的相关资料,如用户名、头像和粉丝数量。<comment>: 包含用户对视频的评论信息。
这种结构使得资料的解析和处理方式变得更加简单高效。
如何获取抖音的XML文件
获取抖音的XML文件主要有以下几种方式,以下将逐一介绍:
方法一:使用抖音API
抖音的开放平台提供了API接口,允许开发者获取特定的资料。通过访问相关API,可以获取到视频、用户及评论等信息。这需要具备一定的编程能力,并且注册开发者账号以获取API密钥。
方法二:网页抓取技术
如果您对编程不太熟悉,可以考虑使用网页抓取工具,如Python的BeautifulSoup或Scrapy库。这些工具可以自动化提取网页中的资料,并将其保存为XML文件。需要注意的是,抓取资料需要遵循相关的法律法规和平台的使用条款。
方法三:使用第三方工具
市场上也有一些第三方工具和插件可以帮助用户获取抖音的XML文件。这些工具通常提供友好的用户界面,只需输入目标视频或用户的链接,就可以一键下载相关资料。
解析获取到的XML文件
获取到XML文件后,我们需要对资料进行解析,以便进行进一步的检视。可以使用Python的xml.etree.ElementTree模块对XML文件进行解析。以下是一个简单的解析示例:
import xml.etree.ElementTree as ET
tree = ET.parse('your_file.xml')
root = tree.getroot()
for video in root.findall('video'):
title = video.find('title').text
duration = video.find('duration').text
print(f'视频标题: {title}, 时长: {duration}秒')资料检视与运用
一旦成功解析了XML文件中的资料,我们就可以进行更深层次的检视。例如,可以通过资料挖掘技术检视用户行为,或者使用可视化工具展示热门视频的动向。这些检视能够为营销策略提供依据,也有助于内容创作者了解市场动向。
总结与展望
通过本文介绍的方法,您可以轻松获取和解析抖音的XML文件,因此深入了解平台的资料。随着短视频市场的不断发展,掌握资料检视技能将使您在职业生涯中占得先机。
相关标签
抖音资料, XML文件, 资料检视, 短视频, 资料源 ```
相关文章





最新文章
-

峰哥网站抖阴:深度探讨新兴社交平台的魅力与难关
2025-03-22 -

抖阴180破解版下载:免费获取最新版本及安装指南
2025-03-22 -

抖阴导航视频录制详细攻略:轻松上手技巧与步骤
2025-03-22 -

抖阴破解版官方安装包下载及使用指南
2025-03-22 -

优质阴抖视频免费网站推荐,尽享高清视频资源分享
2025-03-22 -

如何在抖阴上切换胀号?详细步骤与技巧分享
2025-03-22 -

抖音APP下载1.56版:快速体验最新社交短视频功能!
2025-03-22 -

抖阴app下载安装:轻松制作个性巧音,快速分享乐趣!
2025-03-22
热门文章
-

全新抖音破解版下载:轻松畅享无限视频乐趣
2025-03-21 -

揭秘抖音与抖阴的区别,了解内容平台的真实面貌
2025-03-22 -

“抖阴PCC: 彻底解析新兴社交媒体的魅力与障碍”
2025-03-22 -

抖阴APP iOS破解教程:轻松获取完整版功能与使用技巧
2025-03-21 -

抖阴:探秘那个吊炸天的粗线与其背后的故事
2025-03-21 -

“夜间抖阴:探秘18禁咖绿茵的隐秘世界”
2025-03-21 -

“抖阴各版本下载及使用指南:轻松掌握新功能与特色”
2025-03-21 -

JSBox抖阴:探索全新编程工具与创意实践》
2025-03-21
有话要说...